
9 Exceptional Machine Learning Portfolio Projects: Enhancing Your Data Science Career
In the rapidly evolving field of data science, a robust portfolio of machine learning projects is the cornerstone of professional advancement. These projects not only demonstrate your proficiency in handling complex datasets and implementing advanced algorithms but also showcase your problem-solving skills and creativity.

In this comprehensive editorial, we present nine exceptional machine learning portfolio projects curated to propel your data science career to new heights.
♦ Project 1: Predictive Customer Segmentation for E-Commerce
It is crucial to comprehend customer behavior in the world of e-commerce. This project focuses on creating a predictive model that segments customers based on their browsing and purchasing history. By leveraging techniques like K-means clustering and RFM analysis, you’ll gain insights into customer preferences and tailor marketing strategies accordingly.
◊ Implementation

Predictive Customer Segmentation
- Step A: Data Collection
Objective: Gather comprehensive data from the e-commerce database.
Description: Acquire a diverse range of data encompassing customer interactions, purchase history, and behavior on the e-commerce platform. This dataset will serve as the foundation for customer segmentation.
- Step B: Data Preprocessing
Objective: Prepare the collected data for analysis by addressing any inconsistencies or missing information.
Description: Clean and preprocess the dataset to ensure its quality and reliability. This involves tasks such as handling missing values, removing duplicates, and standardizing formats.
- Step C: RFM Analysis
Objective: Evaluate customer behavior based on reliability, frequency, and monetary (RFM) metrics.
Description: Calculate and assign RFM scores to each customer based on their recent activity, purchase frequency, and total monetary value spent. This analysis forms the basis for further segmentation.
- Step C: Feature Engineering
Objective: Create additional meaningful features that enhance customer segmentation.
Description: Generate new attributes or features derived from the existing dataset. These may include metrics related to customer engagement, product preferences, or interaction patterns.
- Step D: K-means Clustering
Objective: Apply the K-means clustering algorithm to group customers with similar behavior and characteristics.
Description: Utilize the RFM scores and engineered features to cluster customers into distinct groups. K-means is an unsupervised learning technique that identifies natural groupings in the data.
- Step D: Segmented Customer Groups
Objective: Define and interpret the customer segments generated through clustering.
Description: Analyze the characteristics and behaviors of each customer group. Understand the unique traits that define them, such as high spenders, frequent shoppers, or recently active customers.
- Step E: Marketing Strategy
Objective: Tailor marketing strategies and campaigns to address the specific needs and preferences of each customer segment.
Description: Develop personalized marketing initiatives, promotions, and communication channels for each identified group. This targeted approach increases the likelihood of successful engagement.
- Step E: Result Analysis
Objective: Evaluate the effectiveness of the implemented marketing strategies for each customer segment.
Description: Measure the response rates, conversion rates, and overall performance of the marketing efforts. This analysis provides insights into which strategies are most effective for each customer group.
By following these steps, the “Predictive Customer Segmentation for E-Commerce” project aims to enhance customer engagement and drive revenue by leveraging data-driven segmentation strategies.
♦ Project 2: Sentiment Analysis for Social Media Comments
In the era of social media, understanding public sentiment is invaluable for businesses and brands. This project delves into sentiment analysis using natural language processing (NLP) techniques. By training a model on labeled data, you’ll be able to classify comments as positive, negative, or neutral, providing actionable insights for marketing campaigns.
◊ Implementation
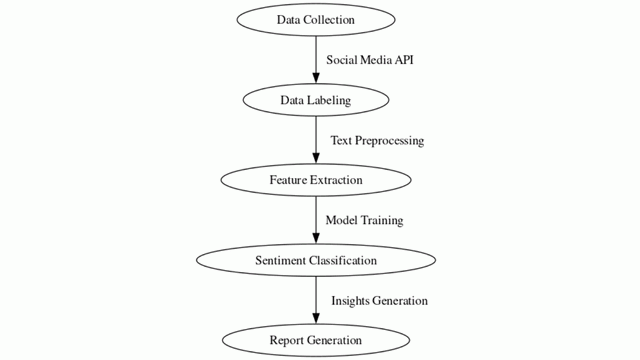
Sentiment Analysis
- Step A: Data Collection
Objective: Retrieve data from social media platforms using their Application Programming Interface (API).
Description: Utilize the API to gather a diverse range of social media comments or reviews. This data will serve as the basis for sentiment analysis.
- Step B: Data Labeling
Objective: Assign sentiment labels (positive, negative, or neutral) to the collected data.
Description: Manually or using automated tools, label each comment or review with its corresponding sentiment category. This labeled dataset is crucial for training the sentiment analysis model.
- Step B: Text Preprocessing
Objective: Prepare the text data for analysis by cleaning and standardizing it.
Description: Clean and preprocess the text by performing tasks such as tokenization, removing stopwords, handling special characters, and applying techniques like stemming or lemmatization.
- Step C: Feature Extraction
Objective: Convert the preprocessed text data into numerical features that can be used by machine learning models.
Description: Utilize techniques like TF-IDF (Term Frequency-Inverse Document Frequency), word embeddings, or other NLP (Natural Language Processing) methods to represent the text as numerical vectors.
- Step C: Model Training
Objective: Select and train a sentiment analysis model on the preprocessed and feature-extracted data.
Description: Choose a suitable model, such as a Naïve Bayes classifier or a deep learning model like an LSTM (Long Short-Term Memory) network. Train the model on the labeled data to learn the relationships between features and sentiment labels.
- Step D: Sentiment Classification
Objective: Use the trained model to classify new text data into sentiment categories.
Description: Apply the trained model to unseen text data to predict the sentiment label for each comment or review. The model will assign a sentiment category (positive, negative, or neutral) to each piece of text.
- Step D: Insights Generation
Objective: Analyze the sentiment predictions to derive meaningful insights.
Description: Summarize and interpret the sentiment analysis results. Understand trends, patterns, and sentiment distributions within the dataset.
- Step E: Report Generation
Objective: Create a report summarizing the sentiment analysis findings and recommendations.
Description: Document the insights, including visualizations or statistics that highlight sentiment trends. Provide actionable recommendations based on the sentiment analysis results.
By following these steps, the “Sentiment Analysis” project aims to understand and categorize the sentiments expressed in social media comments or reviews, enabling businesses and brands to make informed decisions and tailor their strategies accordingly.
♦ Project 3: Fraud Detection in Financial Transactions
Maintaining the integrity of financial transactions is a critical concern for any organization. This project focuses on building a fraud detection system using techniques like anomaly detection and supervised learning. By leveraging historical transaction data, you’ll be able to identify suspicious activities and implement preventive measures.
◊ Implementation

Fraud Detection
- Step A: Data Collection
Objective: Gather comprehensive transaction records from the relevant sources.
Description: Collect transaction data containing information like transaction amounts, timestamps, and user details. This dataset will be used to identify potential fraudulent activities.
- Step B: Feature Engineering
Objective: Create additional relevant features to enhance the fraud detection process.
Description: Generate new attributes derived from the existing transaction data. These features may include metrics related to transaction frequency, amounts, user behavior patterns, and more.
- Step B: Anomaly Detection
Objective: Apply anomaly detection techniques to identify unusual patterns or outliers indicative of potential fraud.
Description: Utilize methods like isolation forest, one-class SVM, or statistical approaches to detect transactions that deviate significantly from normal behavior.
- Step C: Fraudulent Transactions
Objective: Identify and flag transactions that are likely to be fraudulent based on anomaly detection results.
Description: After applying anomaly detection, categorize transactions as either normal or potentially fraudulent. This step distinguishes suspicious transactions from legitimate ones.
- Step D: Alert Generation
Objective: Develop a system that generates alerts for further investigation or action on potentially fraudulent transactions.
Description: Create an automated alerting mechanism to notify relevant parties or systems about flagged transactions. These alerts serve as triggers for further review.
- Step D: Preventive Measures
Objective: Implement preventive measures to mitigate the risk of fraudulent activities.
Description: Integrate strategies like transaction verification, user authentication, or additional security checks to prevent or reduce the occurrence of fraudulent transactions.
- Step E: Result Evaluation
Objective: Assess the effectiveness of the fraud detection system and preventive measures.
Description: Measure the accuracy of identifying fraudulent transactions and evaluate the impact of implemented preventive measures. Use metrics like false positives, false negatives, and the overall detection rate.
- Step E: Continuous Monitoring
Objective: Establish ongoing monitoring to adapt to evolving fraud tactics and patterns.
Description: Continuously monitor transaction data and update the fraud detection system as needed. Stay vigilant for emerging fraud trends and adjust parameters or strategies accordingly.
By following these steps, the “Fraud Detection” project aims to safeguard financial transactions by leveraging data-driven techniques to identify and prevent potential fraudulent activities.
♦ Project 4: Image Classification for Medical Diagnosis
In the field of healthcare, accurate and timely diagnosis is paramount. This project revolves around building an image classification model for medical images. By utilizing deep learning architectures like convolutional neural networks (CNNs), you’ll be able to classify images into various medical conditions, aiding healthcare professionals in their decision-making process.
◊ Implementation

Image Classification
- Step A: Image Dataset
Objective: Obtain a comprehensive dataset of medical images related to the condition you want to diagnose.
Description: Acquire a diverse collection of medical images that represent different cases or conditions. This dataset will serve as the foundation for training the image classification model.
Objective: Prepare the acquired medical images for analysis by applying the necessary transformations.
Description: Perform preprocessing tasks such as resizing, normalizing, and augmenting the images. This ensures consistency and prepares the images for input into the model.
- Step B: Model Architecture
Objective: Design a suitable architecture for the image classification model.
Description: Choose or design a convolutional neural network (CNN) architecture tailored to the specific medical condition. CNNs are particularly effective for image classification tasks.
- Step B: Training
Objective: Train the CNN model on the preprocessed medical image dataset.
Description: Split the dataset into training and validation sets. Train the CNN model using techniques like backpropagation to learn the features and patterns associated with the medical condition.
- Step C: Image Classification
Objective: Utilize the trained model to classify new medical images into relevant categories.
Description: Apply the trained CNN model to unseen medical images to predict the specific condition. The model will assign a class label indicating the diagnosed condition.
- Step C: Diagnostic Reports
Objective: Generate diagnostic reports based on the model’s predictions.
Description: Create reports summarizing the classification results, including information about the predicted condition and confidence scores. These reports serve as a basis for communication with medical professionals.
Objective: Share the diagnostic reports with healthcare professionals for verification and decision-making.
Description: Provide the generated reports to medical professionals for review. They will use the information to validate the model’s predictions and make informed decisions regarding patient care.
- Step D: Feedback Loop
Objective: Gather feedback from medical professionals to refine the model and improve its accuracy.
Description: Incorporate feedback received from healthcare professionals to fine-tune the model. This iterative process helps enhance the model’s performance and reliability.
- Step E: Model Refinement
Objective: Continuously update and refine the model based on feedback and changing medical data.
Description: Make adjustments to the model architecture, hyperparameters, or training data to improve accuracy and generalization. Regular refinement ensures the model remains effective in diagnosing medical conditions.
By following these steps, the “Image Classification for Medical Diagnosis” project aims to provide accurate and timely diagnoses, aiding healthcare professionals in their decision-making process.
♦ Project 5: Time Series Forecasting for Stock Prices
Predicting stock prices is a task of immense financial significance. This project focuses on time series forecasting using methods like ARIMA and LSTM networks. By analyzing historical stock data, you’ll be equipped to make informed investment decisions and develop trading strategies.
◊ Implementation

Time Series Forecasting
- Step A: Stock Price Data
Objective: Obtain historical stock price data for the target asset.
Description: Collect a comprehensive dataset containing historical stock prices, including date, opening price, closing price, high and low prices, and trading volume.
Objective: Prepare the collected stock price data for analysis by addressing any inconsistencies or missing information.
Description: Clean and preprocess the dataset to ensure its quality and reliability. This involves tasks such as handling missing values, removing outliers, and standardizing formats.
- Step B: Model Selection
Objective: Choose an appropriate time series forecasting model based on the nature of the data and the desired level of complexity.
Description: Evaluate various forecasting models such as ARIMA (Auto Regressive Integrated Moving Average), LSTM (Long Short-Term Memory), or other machine learning models suitable for time series data.
- Step B: Training
Objective: Split the dataset into training and testing sets to evaluate the model’s performance.
Description: Divide the preprocessed data into two subsets: one for training the model and another for testing its accuracy. This step ensures the model’s ability to generalize to unseen data.
- Step C: Price Forecasting
Objective: Use the trained model to forecast future stock prices.
Description: Apply the selected forecasting model to generate predictions for the specified time horizon. These forecasts provide insights into the potential future trends of the stock price.
- Step C: Trading Strategies
Objective: Develop trading strategies based on the forecasted prices and market conditions.
Description: Formulate strategies that dictate when to buy, sell, or hold the stock based on the forecasted prices and other relevant market indicators.
- Step D: Investment Decisions
Objective: Make informed investment decisions based on the generated forecasts and trading strategies.
Description: Apply the trading strategies to make decisions regarding buying, selling, or holding the stock. Consider factors like risk tolerance and portfolio diversification.
Objective: Assess the accuracy of the forecasts by comparing predicted prices with actual prices from the testing set.
Description: Calculate performance metrics such as mean absolute error (MAE), root mean square error (RMSE), or others to quantify the accuracy of the forecasts.
- Step E: Iterative Refinement
Objective: Iterate on the model and strategies based on performance feedback.
Description: Continuously monitor the model’s performance and adapt strategies to evolving market conditions. Fine-tune model parameters or consider alternative models for improvement.
By following these steps, the “Time Series Forecasting for Stock Prices” project aims to provide accurate and actionable forecasts to support investment decisions in the stock market.
♦ Project 6: Recommender System for E-Commerce
Enhancing the user experience and driving sales are key objectives for e-commerce platforms. This project focuses on building a personalized recommender system using collaborative filtering and content-based approaches. By understanding user preferences, you’ll be able to provide tailored product recommendations.
◊ Implementation
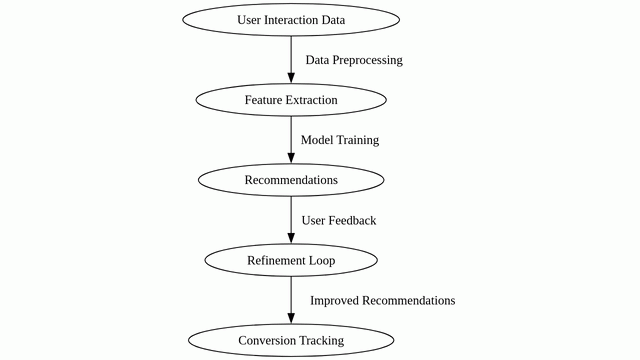
Recommender System
- Step A: User Interaction Data
Objective: Gather comprehensive data on user interactions within the e-commerce platform.
Description: Collect data that includes user behavior such as clicks, views, purchases, and any other relevant interactions. This dataset serves as the foundation for generating personalized recommendations.
Objective: Prepare the collected user interaction data for analysis by addressing any inconsistencies or missing information.
Description: Clean and preprocess the dataset to ensure its quality and reliability. This involves tasks such as handling missing values, removing duplicates, and standardizing formats.
- Step B: Feature Extraction
Objective: Create additional meaningful features that enhance the recommendation process.
Description: Generate new attributes derived from the existing dataset. These features may include metrics related to user preferences, behavior patterns, or product interaction history.
- Step B: Model Training
Objective: Train the recommendation model on the preprocessed user interaction data.
Description: Select and train a recommendation model, such as collaborative filtering or content-based filtering, using the preprocessed data. This step involves learning the relationships between users, products, and their interactions.
- Step C: Recommendations
Objective: Generate personalized product recommendations for users based on their behavior and preferences.
Description: Utilize the trained recommendation model to provide tailored product suggestions to each user. These recommendations are based on the user’s historical interactions with the platform.
- Step C: User Feedback
Objective: Collect feedback from users on the recommended products to refine future recommendations.
Description: Encourage users to provide feedback on the recommended products. This feedback loop helps in understanding user preferences and improving the accuracy of future recommendations.
Objective: Continuously update and refine the recommendation model based on user feedback.
Description: Incorporate the gathered feedback to fine-tune the recommendation algorithm. This iterative process enhances the relevance and accuracy of the recommendations.
- Step D: Improved Recommendations
Objective: Implement strategies to enhance the accuracy and relevance of recommendations.
Description: Apply techniques such as incorporating additional data sources, adjusting model parameters, or experimenting with different recommendation algorithms to further improve the quality of recommendations.
- Step E: Conversion Tracking
Objective: Monitor the conversion rates of recommended products to measure the system’s effectiveness.
Description: Keep track of the conversion rates, which indicate how often recommended products are actually purchased. This metric provides insights into the impact of the recommendation system on sales.
By following these steps, the “Recommender System for E-Commerce” project aims to enhance the user experience and drive sales by providing personalized product suggestions to users based on their behavior and preferences within the e-commerce platform.
♦ Project 7: Language Translation using Sequence-to-Sequence Models
Breaking language barriers is crucial in our interconnected world. This project revolves around building a language translation model using sequence-to-sequence architectures. By training on parallel corpora, you’ll be able to facilitate communication across different linguistic domains.
◊ Implementation

Language Translation
- Step A: Parallel Corpora
Objective: Gather a dataset of parallel corpora, which consists of sets of sentences in different languages with corresponding translations.
Description: Acquire a diverse collection of sentence pairs in different languages. Each sentence in one language should have its corresponding translation in another language.
- Step A: Data Preprocessing
Objective: Prepare the parallel corpora for analysis by applying the necessary transformations.
Description: Clean and preprocess the text data by performing tasks such as tokenization, removing stopwords, handling special characters, and applying techniques like stemming or lemmatization.
- Step B: Model Architecture
Objective: Design a sequence-to-sequence model architecture with attention mechanisms for translation.
Description: Create a neural network architecture suitable for sequence-to-sequence tasks. Include attention mechanisms to enable the model to focus on different parts of the input sequence during translation.
- Step B: Training
Objective: Train the sequence-to-sequence model on the preprocessed parallel corpora.
Description: Split the dataset into training and validation sets. Train the model using techniques like teacher forcing, allowing it to learn the relationships between sentences in different languages.
Objective: Use the trained model to perform language translation on new text inputs.
Description: Apply the trained sequence-to-sequence model to translate sentences from one language to another. The model will generate translated sentences based on the input.
- Step C: Feedback Loop
Objective: Gather feedback on the translated outputs to refine future translations.
Description: Collect feedback on the quality of the translations from users or reviewers. This feedback loop helps in understanding the areas where the model can be improved.
- Step D: Model Refinement
Objective: Continuously update and refine the model based on feedback and changing language data.
Description: Fine-tune the model based on the feedback received. This may involve adjusting hyperparameters, adding more training data, or experimenting with different architectural variations.
- Step D: Improved Translation
Objective: Achieve higher translation accuracy and quality through iterative refinement.
Description: Implement strategies to improve translation quality, such as incorporating more advanced models, using larger datasets, or fine-tuning existing models.
Objective: Integrate the language translation model into applications or platforms for practical use.
Description: Embed the refined translation model into applications, websites, or systems where translation services are required. Ensure seamless integration for end-users.
By following these steps, the “Language Translation using Sequence-to-Sequence Models” project aims to break language barriers and facilitate effective communication across different linguistic domains.
♦ Project 8: Customer Churn Prediction for Subscription Services
Retaining customers is a top priority for subscription-based businesses. This project focuses on building a customer churn prediction model using techniques like logistic regression and random forests. By analyzing customer behavior and engagement metrics, you’ll be able to implement targeted retention strategies.
◊ Implementation

Customer Churn Prediction
- Step A: Customer Interaction Data
Objective: Gather comprehensive data on customer interactions with the business.
Description: Collect data that includes customer behavior such as purchase history, support interactions, feedback, and any other relevant interactions. This dataset serves as the foundation for predicting customer churn.
- Step A: Data Preprocessing
Objective: Prepare the collected customer interaction data for analysis by addressing any inconsistencies or missing information.
Description: Clean and preprocess the dataset to ensure its quality and reliability. This involves tasks such as handling missing values, removing duplicates, and standardizing formats.
Objective: Identify and select relevant features that are indicative of customer churn.
Description: Analyze the preprocessed data to determine which features are most informative for predicting churn. These features may include factors like purchase frequency, customer satisfaction scores, and engagement metrics.
- Step B: Model Training
Objective: Train a churn prediction model using the selected features.
Description: Choose an appropriate machine learning algorithm, such as logistic regression, decision trees, or a neural network. Train the model on the preprocessed and feature-selected data to learn the relationships between features and churn.
- Step C: Churn Prediction
Objective: Use the trained model to predict which customers are at risk of churning.
Description: Apply the trained churn prediction model to classify customers into categories: likely to churn or likely to stay. This step helps identify high-risk customers who may need retention efforts.
Objective: Develop strategies to retain customers identified as at risk of churning.
Description: Create targeted retention campaigns or initiatives to engage with and incentivize customers who are likely to churn. These efforts may include special offers, personalized outreach, or improved customer support.
- Step D: Result Evaluation
Objective: Assess the effectiveness of the retention strategies by measuring customer retention rates.
Description: Monitor how many customers identified as at risk of churning were successfully retained due to the implemented strategies. Evaluate the impact of these efforts on overall customer retention.
- Step D: Iterative Optimization
Objective: Continuously refine and optimize the churn prediction model and retention strategies.
Description: Use feedback from the results to fine-tune the model and strategies. This iterative process ensures that the system becomes increasingly effective at retaining customers.
Objective: Achieve the highest possible customer retention rate through continuous optimization.
Description: Implement strategies that maximize customer retention based on the insights gained from the iterative optimization process. The goal is to keep as many customers as possible over time.
By following these steps, the “Customer Churn Prediction and Retention” project aims to proactively identify and retain customers who are at risk of churning, ultimately contributing to business growth and customer satisfaction.
♦ Project 9: Object Detection for Autonomous Vehicles
Advancements in autonomous vehicles have the potential to revolutionize transportation. This project focuses on building an object detection system using deep learning techniques. By processing real-time camera feeds, you’ll be able to identify and track objects in the vehicle’s surroundings, contributing to enhanced safety and navigation.
◊ Implementation

Object Detection
- Step A: Camera Feed
Objective: Capture real-time visual information from the vehicle’s cameras.
Description: Utilize cameras placed on the vehicle to continuously feed images or video streams to the autonomous system. This visual input serves as the primary source of information for navigation and object detection.
Objective: Preprocess the incoming images to enhance their quality and suitability for analysis.
Description: Apply techniques such as noise reduction, contrast adjustment, and resizing to prepare the images for further processing. This step ensures that the visual data is in an optimal format for analysis.
- Step B: Object Detection Model
Objective: Implement an object detection model to identify and locate objects in the camera feed.
Description: Train or employ a pre-trained object detection model (e.g., YOLO, SSD) to detect various objects in the images, such as vehicles, pedestrians, and traffic signs.
- Step B: Real-time Tracking
Objective: Continuously track the detected objects in real-time to monitor their movements.
Description: Apply tracking algorithms (e.g., Kalman filters, Hungarian algorithm) to associate detected objects across frames and predict their trajectories.
Objective: Utilize the object detection and tracking information to make navigational decisions.
Description: Process the tracked objects’ information to determine safe and efficient routes, accounting for obstacles, traffic rules, and road conditions.
- Step C: Safety Protocols
Objective: Implement safety measures to ensure the vehicle operates securely.
Description: Integrate safety protocols such as collision detection and emergency braking systems to respond to potential hazards or unexpected situations.
- Step D: Feedback Loop
Objective: Gather feedback on the system’s performance from real-world testing and usage.
Description: Conduct extensive testing in various environments and driving conditions. Collect feedback from the vehicle’s behavior, interactions with objects, and adherence to safety protocols.
Objective: Use feedback to improve the performance of the object detection and tracking models.
Description: Fine-tune the object detection and tracking algorithms based on the feedback received. This may involve retraining the models with additional data or adjusting parameters.
- Step E: Optimized Detection
Objective: Achieve optimized object detection and tracking for reliable autonomous driving.
Description: Implement strategies to enhance the efficiency and accuracy of object detection and tracking, ensuring the system operates smoothly and safely under various conditions.
By following these steps, the “AI-Powered Autonomous Vehicle System” project aims to enable a vehicle to autonomously navigate, detect objects, and ensure safe driving experiences in real-world environments.
Summary
Incorporating these diverse and challenging machine learning projects into your portfolio will not only demonstrate your expertise but also position you as a standout candidate in the competitive field of data science. Remember, continuous learning and refinement are key to staying at the forefront of this dynamic field. Start building these projects today and take your data science career to new heights!
Conclusion
In conclusion, embarking on these nine exceptional machine learning portfolio projects is a definitive step towards elevating your data science career. Each project offers unique insights and practical experience in handling complex datasets, implementing advanced algorithms, and deriving meaningful conclusions.
By showcasing your proficiency in diverse domains such as customer segmentation, sentiment analysis, fraud detection, medical diagnosis, stock price forecasting, recommender systems, language translation, customer churn prediction, and object detection, you position yourself as a versatile and capable data scientist.
Remember, the journey doesn’t end with project completion. Continual learning, refinement, and exploration of emerging technologies and methodologies are crucial to staying ahead in the ever-evolving field of data science. Seize these projects as opportunities to not only enhance your skills but also contribute to real-world solutions and innovations.
FAQs
Choosing the right project largely depends on your interests, existing skill set, and career goals. Consider projects that align with your passions and allow you to delve into areas you’re curious about. Additionally, start with projects that match your current proficiency level and gradually progress to more complex ones.
Do I need prior experience in machine learning to undertake these projects?
While prior experience in machine learning is beneficial, these projects are designed to accommodate a range of proficiency levels. Each project provides detailed implementation steps and resources to guide you through the process. Additionally, leveraging online communities, forums, and tutorials can offer invaluable support along the way.
How much time does it usually take to finish a project?
The duration required to complete each project may vary based on its complexity and your familiarity with the techniques involved. While some tasks can be finished in a few weeks, others can take a few months. The key is to focus on understanding the concepts and ensuring a high-quality outcome, rather than rushing through the process.
Can I modify or customize these projects to suit specific industries or applications?
Absolutely. These projects serve as a foundation that can be tailored to various industries or applications. For instance, the customer segmentation project can be adapted for retail, e-commerce, or even healthcare. Feel free to modify parameters, datasets, and algorithms to cater to specific needs and industries.
How can I showcase these projects in my portfolio effectively?
When showcasing these projects in your portfolio, emphasize the problem statement, the techniques employed, and, most importantly, the results achieved. Provide clear visualizations and insights derived from the project. Additionally, include the code, if possible, to demonstrate your technical proficiency. Remember, a well-documented and visually appealing portfolio can significantly enhance your professional profile.
By undertaking these projects and effectively showcasing them in your portfolio, you not only demonstrate your expertise but also contribute meaningfully to the field of data science. Stay curious, keep learning, and let your passion for data science drive you towards even greater heights in your career.
Get access all prompts: https://bitly.com/projects





